サイト上の特定の情報を抜き出す(その2)
2022/1/24 2022/4/15
Webスクレイピングの練習の「その2」です。
ドラクエウォークの攻略サイトから、イベントモンスターの発生期間を取得します。
まずは目で見て確認
取得したHTMLコードを目で確認します。
まず、実際のサイトはこんな感じです。こちらのサイトの情報を拝借しております(https://game8.jp/dqwalk/420884)。

保存したHTMLコードから「出現」で検索してみます。
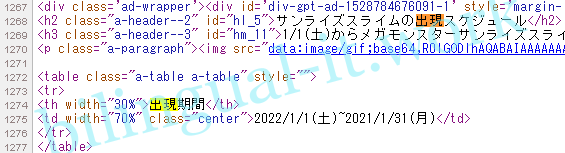
見つけました。<h2>タグのところに情報があったので、とりあえず取得を試みてみます。
Pythonで特定のHTMLコードを取得
Pythonコードは以下のような感じです。
# Import libraries - General -
import os
# Import libraries - Specialized -
from bs4 import BeautifulSoup
File_Name = "Sunrise_Slime_20220107-165318.html"
with open(File_Name, "r") as file:
html = file.read()
soup = BeautifulSoup(html, "html.parser")
elms = soup.find_all("h2")
for i in elms:
print(i)出力結果は以下の通りです。
<h2 class="a-header--2" id="hl_1">サンライズスライムの弱点・耐性|基本情報</h2>
<h2 class="a-header--2" id="hl_2">サンライズスライムの攻略ポイントとおすすめ装備</h2>
<h2 class="a-header--2" id="hl_3">サンライズスライムの行動パターンと対策</h2>
<h2 class="a-header--2" id="hl_4">サンライズスライムのおすすめパーティ編成</h2>
<h2 class="a-header--2" id="hl_5">サンライズスライムの出現スケジュール</h2>
<h2 class="a-header--2" id="hl_6">サンライズスライムのこころ性能</h2>
<h2 class="a-header--2" id="hl_7">関連記事</h2>
<h2 class="a-header--2">ドラクエウォークプレイヤーにおすすめ</h2>
<h2 class="a-header--2">コメント</h2>
<h2 class="a-header--2">記事を書いている攻略メンバー</h2>
<h2 class="c-heading__title">攻略メニュー</h2>
<h2 class="c-heading__title">ランキング</h2>
<h2 class="c-heading__title">人気ゲーム</h2>
<h2 class="c-heading__title">おすすめゲーム</h2>
<h2 class="c-heading__title">新作ゲーム</h2>
<h2 class="c-heading__title">新着コメント</h2>
<h2 class="c-heading__title">権利表記</h2>よく見ると、私の欲しい情報「サンライズスライムの出現スケジュール」には「id=hl_5」という属性があるようです。これをピンポイントで抜き出します。Pythonコードはこんな感じです。
# Import libraries - General -
import os
# Import libraries - Specialized -
from bs4 import BeautifulSoup
File_Name = "Sunrise_Slime_20220107-165318.html"
with open(File_Name, "r") as file:
html = file.read()
soup = BeautifulSoup(html, "html.parser")
H2_id_hl_5 = soup.find_all("h2", {"id":"hl_5"})
print(str(H2_id_hl_5[0]))
print("---")
print(str(H2_id_hl_5[0].string))出力結果は以下の通りです。
<h2 class="a-header--2" id="hl_5">サンライズスライムの出現スケジュール</h2>
---
サンライズスライムの出現スケジュール
- めっさん
当サイトの管理人。ニューヨークの大学を飛び級で卒業。その後日系企業でグローバル案件に携わる。大小様々な企業を転々としながら、マレーシアやアメリカへの赴任経験を持つ。バイリンガルITエンジニアとしていかに楽に稼ぐか日々考えている。年齢は秘密だけど定年も間近かな。
- 企業あるある。矛盾する施策 2026/3/24
- バイリンガルITエンジニアの仕事・年収・転職のリアル 2026/3/17
- Keep Yourself Busyやってみて 2026/3/10
- アメリカでのオフィス引っ越しの注意点 2026/3/3
- 我が家のクラウドストレージ事情 2026/2/24