Python試験対策いろいろ(その3)
Pythonの基礎認定試験合格に向けて勉強していますが、個人的なメモを投稿していこうと思います。
体裁は気にせず記載するため、読みにくいかも知れませんが、同じく勉強をしている方のお役に少しでも立てれば良いと思います。
Pythonの基本
- sys.pathが初期化されている場所は、PYTHONPATH、インストールごとのデフォルト、入力スクリプト。
- モジュール読み込みの高速化のため、Pythonはコンパイル済みのモジュールを「__python_cache__」ディレクトリにmodule.バージョン名.pycの名前でキャッシュする。
- モジュールの中では、グローバル変数「__name__」の値としてモジュール名(文字列)がセットされている。
- モジュールと「__init__.py」を含むディレクトリをパッケージと言う。
- 標準モジュールjsonは、Pythonのデータ階層構造をとって、文字列表現に変換できる。このプロセスをシリアライズと言う。
- raise分を用いることで、意図した例外を発生させることができる。
- 発生した例外に値が付く場合があり、それを例外の引数と呼んでいる。except説では例外名の後に変数を指定できる。この変数には例外インスタンスが紐づけられており、例外インスタンスには「__str__()」が定義されている。
- ユーザがキーボード操作で割り込みを発生させた場合はKeyboardInterrupt例外が発生する。
- 変数を事前に宣言する必要はない。
- コンパイルは必要ない。
- 文字コードはデフォルトのUTF-8か、ASCIIが最良である。特に国際的な環境で使用される場合には重要である。
- モジュールがインポートされる際に、インタープリタが検索する順序は、ビルトインモジュール、sys.path変数で得られるディレクトリである。なお、シンボリックリンクが置いてあるディレクトリは含まれない。
- クラスに「__init__()」メソッドが定義されている場合、新規作成されたインスタンスに対して自動的にこのメソッドがコールされる。このメソッドには複数の引数を与えることができる。
- pip uninstallでパッケージを指定すると仮想環境から削除が可能だが、その際複数のパッケージを指定することができる。
- パッケージのアップグレードをする際は「pip install –upgrade package_name」などとする。
- デフォルトでは、ユーザディレクトリの「.python_history」という名前のファイルに履歴を保存する。
- sys.pathには、①入力されたスクリプトのあるディレクトリ、②PYTHONPATH、③インストールごとのデフォルトが含まれる。
プライマリ/セカンダリプロンプト
プライマリプロンプトは「>>>」で、セカンダリプロンプトは「…」である。セカンダリプロンプトとは、例えばfor文やif文の直後の行である。
>>> def function():
... print("Here's a secondary prompt.")
...
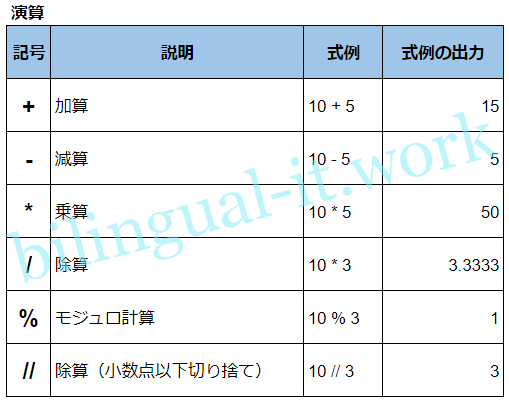
>>>演算(加減乗除等)
基本的な加減乗除に加えて、除算の際に余りを無視するものや余りのみを算出するもの(モジュロ)がある。
文字列の演算
演算と呼ぶか個人的にしっくりこないが、文字列も足したり掛けたりできる。
例えば、同じ文字列を複数回繰り返す場合には掛け算で使う「*」を使う。
word = "ass" * 2 + "ination"
print(word)
# Output Result
# assassinationちなみに、英語でassとは……という意味ですが、それを2回繰り返して、「ination」を付け加えると、assassinationという「暗殺」という意味の英語になります。
文字列のスライシングと置換
文字列に対してスライシングを行う場合、どのような値([A:B]におけるいかなるAまたはB)をとってもエラーにはなりません。しかし、文字列は特定のインデックスを指定しても、その文字を書き換えることはできません。
greeting = "TodayIsAWonderfulDay"
print(greeting[:])
print(greeting[1000:])
print(greeting[3:1000])
print(greeting[:1000] + "J")
greeting[3] = "J"上記コードに対する結果ですが、最終行の箇所でエラーとなっています。
TodayIsAWonderfulDay
ayIsAWonderfulDay
TodayIsAWonderfulDayJ
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-3-2444e990f6a0> in <module>()
7 print(greeting[:1000] + "J")
8
----> 9 greeting[3] = "J"
TypeError: 'str' object does not support item assignment関数で複数の引数の受取
関数の定義で引数を指定する時、「*」を付けることで複数の値をタプルとして受け取れます。
def func(arg1, *arg2):
print(arg1)
print(arg2)
for i in arg2:
print(i, end=",")
func(1,2,34,5,6,76,78,8,98,9,0)
# Output Result
# 1
# (2, 34, 5, 6, 76, 78, 8, 98, 9, 0)
# 2,34,5,6,76,78,8,98,9,0,なお、辞書として受け取る場合は「**」をつけます。
リストの操作(値の挿入、追加、削除等)
リストの値は挿入したり、削除したり、追加したりできます。
list = [3, 5, 6, "A", 7, 9, "B"]
list.remove("A")
print(list, "-> after remove()")
list.pop()
print(list, "-> after pop()")
list.insert(0,1)
print(list, "-> after insert()")
list.append(10)
print(list, "-> after append()")
list.sort(reverse = True)
print(list, "-> after sort(reverse == True)")
# Output Result
# [3, 5, 6, 7, 9, 'B'] -> after remove()
# [3, 5, 6, 7, 9] -> after pop()
# [1, 3, 5, 6, 7, 9] -> after insert()
# [1, 3, 5, 6, 7, 9, 10] -> after append()
# [10, 9, 7, 6, 5, 3, 1] -> after sort(reverse == True)文字列の比較
どのような場合に使うのか私には分かりませんが、文字列の大小を比較することができます。※「文字列の大小」という表現に私もピンと来ていませんが。
文字はコードポイントという番号が振られています。アルファベットに関して言えば、大文字があって、その後に小文字がきます。つまり、大文字の方が小文字よりも小さいコードポイントを持っています。このコードポイントで大小の比較が可能です。
print("Matplotlib: M is ", ord("M"))
print("Numpy: N is ", ord("N"))
print("pandas: p is ", ord("p"))
print("scikit-learn: s is ", ord("s"))
print("NOTE:\nCapital A is", ord("A"), "and small a is", ord("a"))
print("bb" < "bc" )
# Output Result
# Matplotlib: M is 77
# Numpy: N is 78
# pandas: p is 112
# scikit-learn: s is 115
# NOTE:
# Capital A is 65 and small a is 97
# Trueコマンドプロンプトからの引数渡し
sysモジュールをインポートして、argv[N]として受け取れます。複数の引数の場合はNでインデックス指定をしますが、一番最初の値(N=0)はスクリプト名となります。
statisticsモジュール
もはや英語の問題と思いましたが、とある模擬試験に出てきたのでまとめておきます。
| 平均値 | mean, average |
| 中央値 | median |
| 最頻値 | mode |
| 分散 | variance |
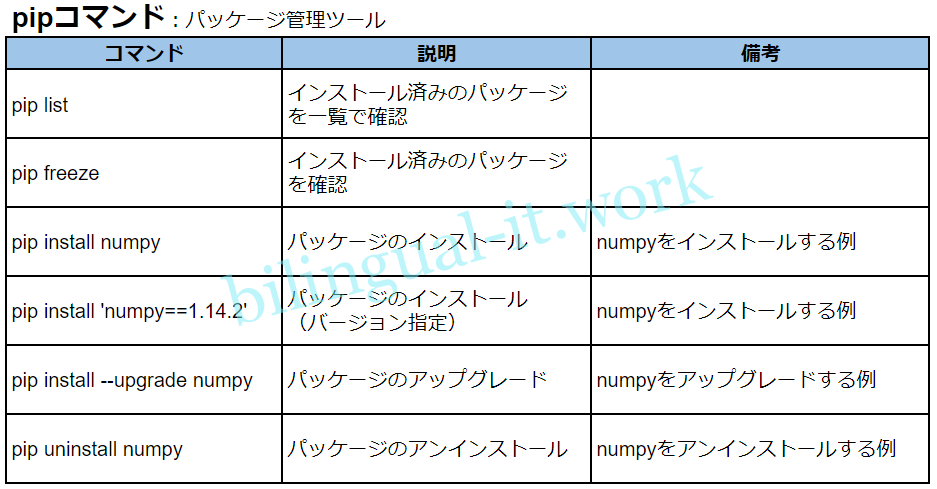
pipコマンドの代表的な使い方
関数にリスト型や辞書型を引数として渡す
関数定義時の引数名に「*」を1つないしは2つ付け加えることで、リスト型や辞書型の値を引数として受け取れます。1つの場合はタプル型やリスト型をタプル型として受け取り、2つの場合は辞書を受け取れます。
def func(str, *list, **dictionary):
print(f"str: {str}")
print(f"list: {list}")
print(f"dictionary: {dictionary}")
func("Apple", "Mac", "iPhone", "iPad", Pirce=1000000, Model=13, Color="Orange")
# Output Result
# str: Apple
# list: ('Mac', 'iPhone', 'iPad')
# dictionary: {'Pirce': 1000000, 'Model': 13, 'Color': 'Orange'}inまたはnot inで辞書内の値を検査する場合
辞書(ディクショナリ)型では、キーとバリューの組み合わせの値を持つが、inまたはnot inの帰属性判定子を使用した場合、キーを探索する。
以下の例では、Appleを探索するが、Appleはバリューのためキーに含まれず、Fruitを探索した場合、キーに含まれる、ということになる。
dict = {"Fruit":"Apple", "Price":500, "City":"Kuala Lumpur"}
if "Apple" in dict:
print(f"Apple is in {dict}")
else:
print(f"Apple is not in {dict}")
if "Fruit" in dict:
print(f"Fruit is in {dict}")
else:
print(f"Fruit is not in {dict}")
# Output Result
# Apple is not in {'Fruit': 'Apple', 'Price': 500, 'City': 'Kuala Lumpur'}
# Fruit is in {'Fruit': 'Apple', 'Price': 500, 'City': 'Kuala Lumpur'}
- めっさん
当サイトの管理人。ニューヨークの大学を飛び級で卒業。その後日系企業でグローバル案件に携わる。大小様々な企業を転々としながら、マレーシアやアメリカへの赴任経験を持つ。バイリンガルITエンジニアとしていかに楽に稼ぐか日々考えている。年齢は秘密だけど定年も間近かな。
- バイリンガルITエンジニアとしてアピールする方法 2026/6/23
- AIの誤使用はやめていただきたい 2026/6/16
- バイリンガルITエンジニアのデメリット 2026/6/9
- メーカの通信要件は信じるな(Meraki等) 2026/6/2
- アクセスポイントはL2デバイスかL3デバイス 2026/5/26
本日試験を受けてきます。
Pythonの基本の中にかなりコンパクトにまとめられており、都度確認するのに大変助かっております。
うかってかえってやるぜええええ
okeiさん
コメントありがとうございます!
(多忙ゆえ気付くのが遅れてしまいました…)
少しでもお役に立てて嬉しいです。
無事受かったことを期待してます!